anvi-display-functions
Table of Contents
Start an anvi'o interactive display to see functions across genomes.
🔙 To the main page of anvi’o programs and artifacts.
Authors

Can consume
functions ![]() genomes-storage-db
genomes-storage-db ![]() internal-genomes
internal-genomes ![]() external-genomes
external-genomes ![]() groups-txt
groups-txt ![]()
Can provide
interactive ![]() functional-enrichment-txt
functional-enrichment-txt ![]()
Usage
For a given annotation source for functions, this program will display distribution patterns of unique function names (or accession numbers) across genomes stored in anvi’o databases.
It is a powerful way to analyze differentially occurring functions for any source of annotation that is shared across all genomes.
Currently, anvi-display-functions can work with any combination of genomes from external-genomes, internal-genomes, and genomes-storage-db.
If you are only interested in a text output, see the program anvi-script-gen-function-matrix-across-genomes that can report functions-across-genomes-txt files.
Quick & Simple Run
The simplest way to run this program is as follows:
anvi-display-functions -e external-genomes \ --annotation-source KOfam \ --profile-db KOFAM-PROFILE.db
You can replace the annotation source based on what is available across your genomes. You can use the program anvi-db-info to see all available function annotation sources in a given contigs-db or genomes-storage-db. You can also use the program anvi-import-functions to import ANY kind of functional grouping of your genes and use those ad hoc functional sources to display their distribution across genomes. Please see functions for more information on functions and how to obtain them.
Please note that a profile-db will be automatically generated for you. Once it is generated, the same profile database can be visualized over and over again using anvi-interactive in manual mode, without having to retain any other files.
Combining genomes from multiple sources
You can run this program by combining genomes from multiple sources:
anvi-display-functions -e external-genomes \ -i internal-genomes \ -g genomes-storage-db \ --annotation-source KOfam \ --profile-db KOFAM-PROFILE.db
This way, you can bring together functions in your metagenome-assembled genomes, the isolates you have acquired from external sources, and even genomes in an anvi’o pangenome into a single framework in a disturbingly easy fashion.
Performing functional enrichment analysis for free
This is an optional step, but may be very useful for some investigations. If your genomes are divided into meaningful groups, you can also perform a functional enrichment analysis while running this program. All you need to do for this to be included in your analysis is to provide a groups-txt file that describes which genome belongs to which group:
anvi-display-functions -e external-genomes \ --groups-txt groups-txt --annotation-source KOfam \ --profile-db KOFAM-PROFILE.db
If you are using multiple sources for your genomes, you may not immediately know which genomes to list in your groups-txt file. In that case, you can first run the program with this additional parameter,
anvi-display-functions -e external-genomes \ -i internal-genomes \ -g genomes-storage-db \ --annotation-source COG20_FUNCTION \ --profile-db COGS-PROFILE.db \ --print-genome-names-and-quit
In which case anvi’o would report all the functions once it recovers everything from all sources, and print them out for you to create a groups file before re-running the program with it.
This analysis will add the following additional layers in your interactive display: ‘enrichment_score’, ‘unadjusted_p_value’, ‘adjusted_q_value’, ‘associated_groups’. See functional-enrichment-txt to learn more about these columns.
Aggregating functions using accession IDs
Once it is run, this program essentially aggregates all function names that occur in one or more genomes among the set of genomes found in input sources. The user can ask the program to use accession IDs to aggregate functions rather than function names:
anvi-display-functions -e external-genomes \ --annotation-source KOfam \ --profile-db KOFAM-PROFILE.db \ --aggregate-based-on-accession
While the default setting, which is to use function names, will be appropriate for most applications, using accession IDs instead of function names may be important for specific purposes. There may be an actual difference between using functions or accession to aggregate data since multiple accession IDs in various databases may correspond to the same function. This may lead to misleading enrichment analyses downstream as identical function annotations may be over-split into multiple groups. Thus, the default aggregation method uses function names.
Aggregating functions using all function hits
This is a bit confusing, but actually it is not. In some cases a gene may be annotated with more than one function names. This is a decision often made at the function annotation tool level. For instance anvi-run-ncbi-cogs may yield two COG annotations for a single gene because the significance score for both hits may exceed the default cutoff. While this can be useful in anvi-summarize output where things should be most comprehensive, having some genes annotated with multiple functions and others with one function may over-split them (since in this scenario a gene with COGXXX and COGXXX;COGYYY would end up in different bins). Thus, anvi-display-functions will will use the best hit for any gene that has multiple hits. But this behavior can be turned off the following way:
anvi-display-functions -e external-genomes \ --annotation-source KOfam \ --profile-db KOFAM-PROFILE.db \ --aggregate-using-all-hits
The min-occurrence limit
You can choose to limit the number of functions to be considered to those that occur in more than a minimum number of genomes:
anvi-display-functions -e external-genomes \ --annotation-source KOfam \ --profile-db KOFAM-PROFILE.db \ --min-occurrence 5
Here the --min-occurrence 5 parameter will exclude any function that appears to occur in less than 5 genomes in your collection.
A real-world example
Assume we have a list of external-genomes that include three different species of Bifidobacterium. Running the following command,
anvi-display-functions --external-genomes Bifidobacterium.txt \ --annotation-source COG20_FUNCTION \ --profile-db COG20-PROFILE.db \ --min-occurrence 3
Would produce the following display by default, where each layer is one of the genomes described in the external-genomes file, and each item is a unique function name that occur in COG20_FUNCTION (which was obtained by running anvi-run-ncbi-cogs on each contigs-db in the external genomes file) that were found in more than three genomes:
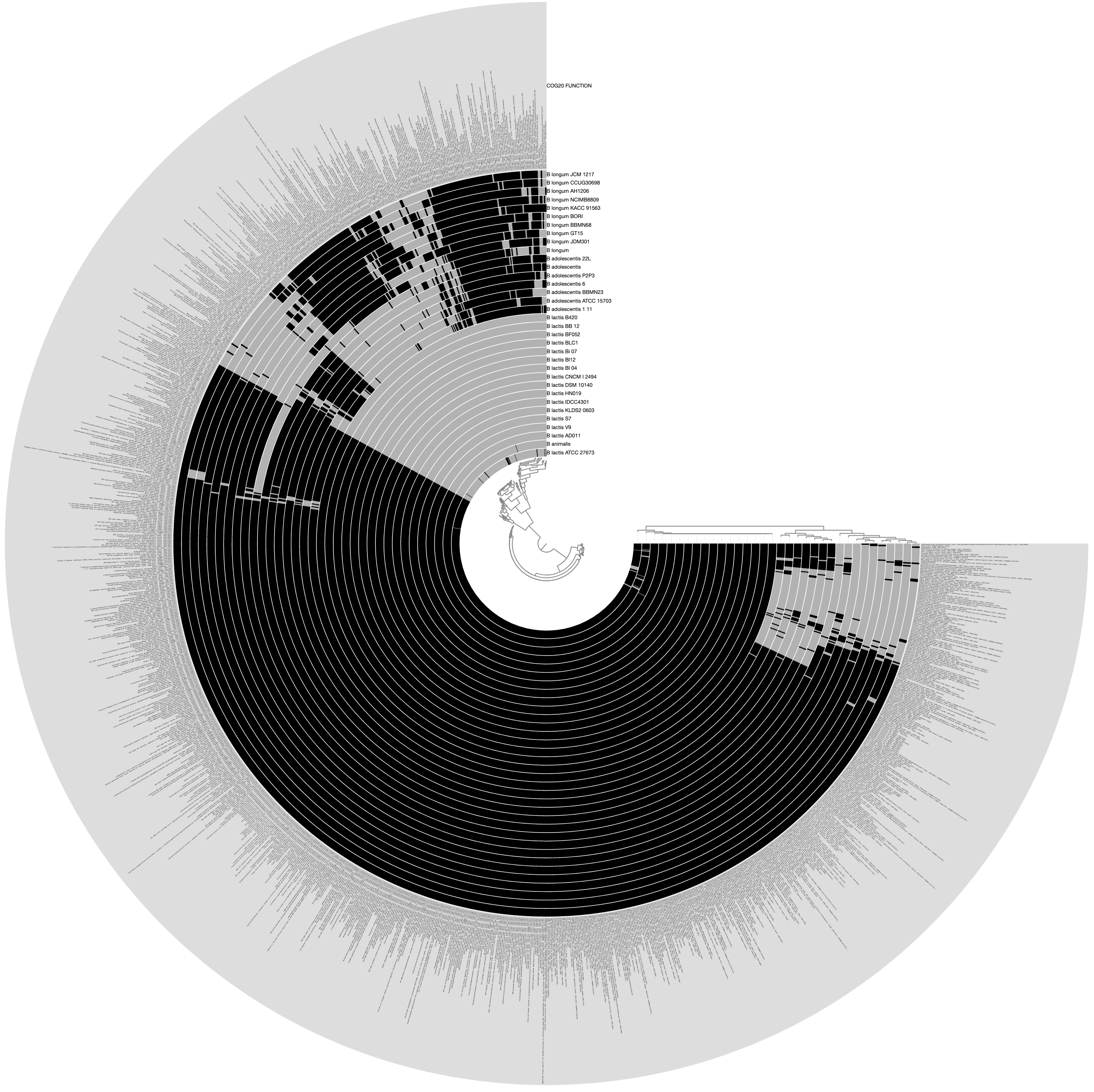
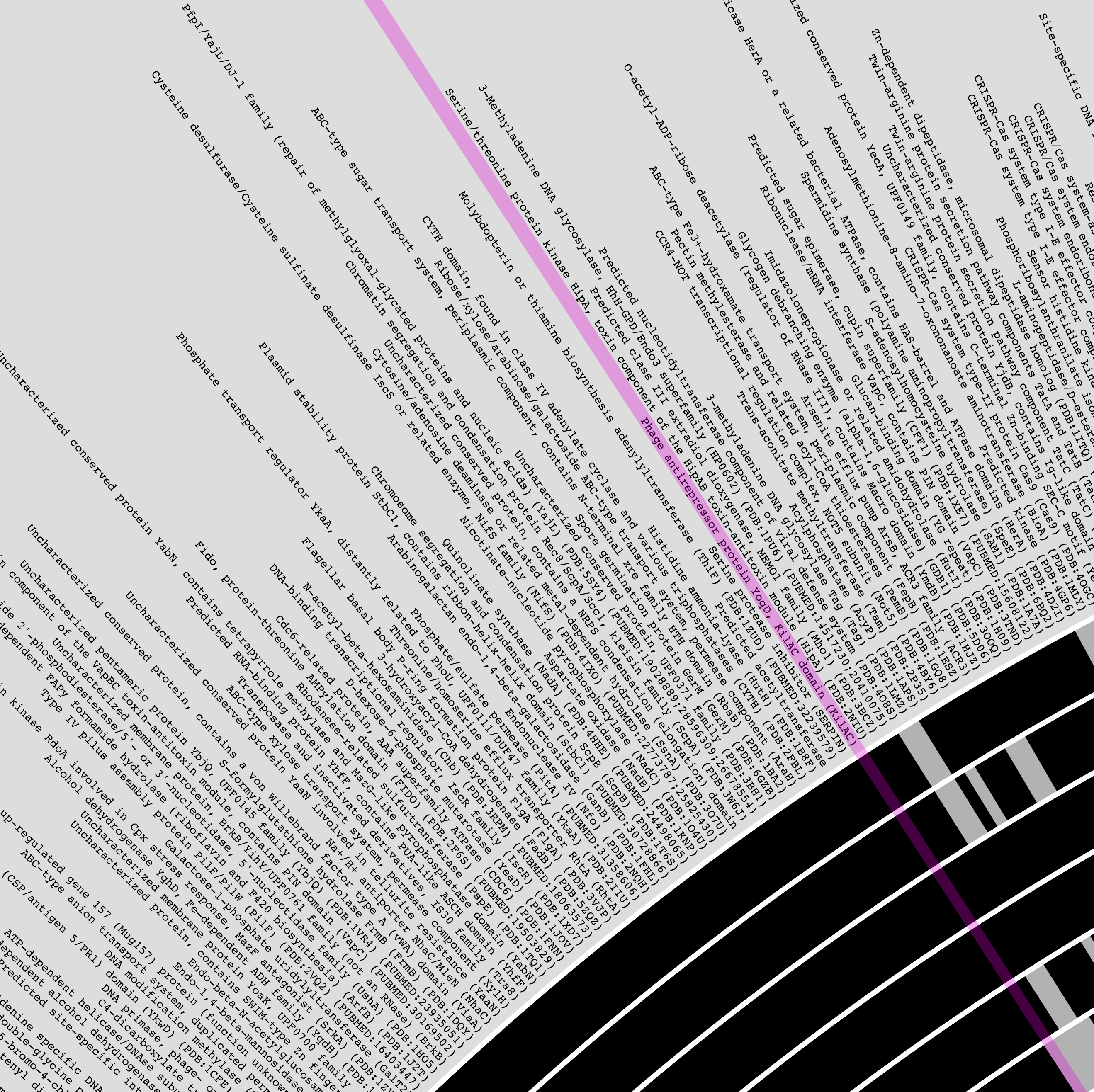
The outermost layer shows the function names:
After a quick prettification through the interactive interface, leads to a cleaner display of three distinct species in this group, and functions that are uniquely enriched in either of them:
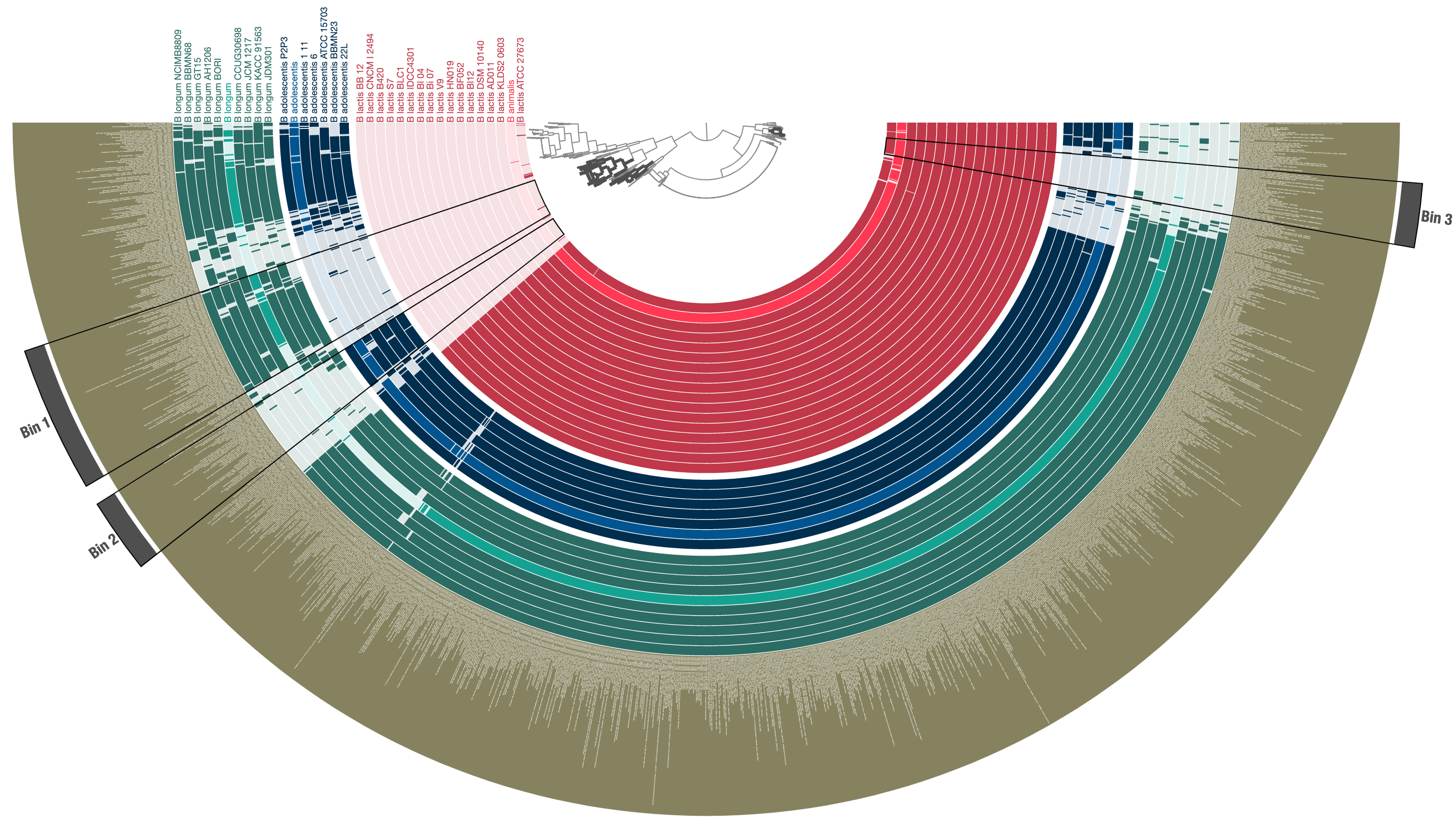
Now the resulting profile-db can be used by anvi-interactive to re-visualize these data, or can be shared with the community without sharing the underlying contigs databases.
Edit this file to update this information.
Additional Resources
Are you aware of resources that may help users better understand the utility of this program? Please feel free to edit this file on GitHub. If you are not sure how to do that, find the __resources__ tag in this file to see an example.